|
Haodong Li (李浩东) PhD Student @ UC San Diego | Research Scientist Intern @ Adobe I'm a PhD student at UC San Diego, working with Prof. Manmohan Chandraker. I'm also a research scientist intern at Adobe Research, working with Dr. Shaoteng Liu and Dr. Zhe Lin. I'm interested in generative world modeling in both pixels and 3D. Previously, I got my MPhil degree from HKUST, working with Prof. Ying-Cong Chen. I got my BEng degree from Zhejiang University. I spent a wonderful summer at Tencent Hunyuan as a research scientist intern. Feel free to reach out if you have anything to discuss! 🚀
Email: hal211@ucsd.edu, haodongl@adobe.com Google Scholar / CV / Github / Twitter (X) / Linkedin / Huggingface |

|
Selected Publications✱Both authors contributed equally. |
|
|
Rolling Sink:
Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion
Haodong Li, Shaoteng Liu, Zhe Lin, Manmohan Chandraker
arXiv 2026
Rolling Sink aims to bridge the gap between limited-horizon training and open-ended testing in autoregressive video diffusion. Built on Self Forcing (trained on only 5s clips), Rolling Sink effectively scales the autoregressive video synthesis to ultra-long durations (e.g., 5-30 minutes) at test time, with consistent subjects, stable colors, and smooth motions. |

|
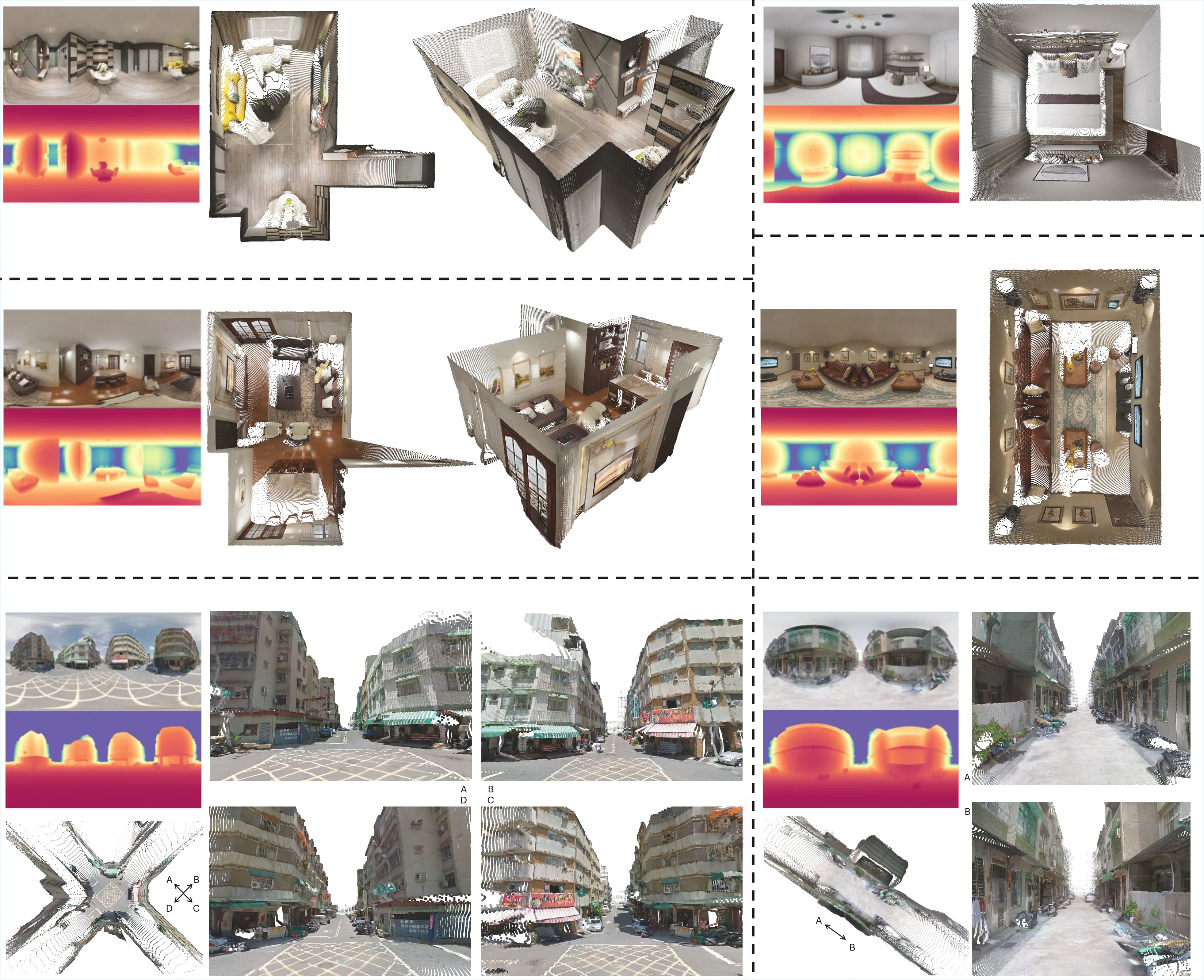
DA2: Depth Anything in Any Direction
Haodong Li, Wangguangdong Zheng, Jing He, Yuhao Liu, Xin Lin, Xin Yang, Ying-Cong Chen, Chunchao Guo
ICLR 2026
Powered by large-scale training data curated from our panoramic data curation engine, and the SphereViT for addressing the spherical distortions in panoramas, DA2 is able to predict dense, scale-invariant distance from a single 360° panorama in an end-to-end manner, with remarkable geometric fidelity and strong zero-shot generalization. |


|
Lotus-2: Advancing Geometric Dense Prediction with Powerful Image Generative Model
Jing He, Haodong Li✱, Mingzhi Sheng✱, Ying-Cong Chen
arXiv 2025
Lotus-2 is an advanced two-stage deterministic framework for monocular geometric dense estimation built upon FLUX. By effectively analyzing the DiT-based rectified-flow formulation and leveraging pre-trained generative model as a deterministic world prior, Lotus-2 achieves SoTA performance while producing significantly finer details. |


|
Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Jing He✱, Haodong Li✱, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, Ying-Cong Chen
ICLR 2025
Lotus is a diffusion-based visual foundation model with a simple yet effective adaptation protocol, aiming to fully leverage the pre-trained diffusion's powerful visual priors for dense prediction. With minimal training data, Lotus achieves SoTA performance in two key geometry perception tasks, i.e., zero-shot monocular depth and normal estimation. |



|
DisEnvisioner: Disentangled and Enriched Visual Prompt for Image Customization
Jing He✱, Haodong Li✱, Yongzhe Hu, Guibao Shen, Yingjie Cai, Weichao Qiu, Ying-Cong Chen
ICLR 2025
Characterized by its emphasis on the interpretation of subject-essential attributes, the proposed DisEnvisioner effectively identifies and enhances the subject-essential feature while filtering out other irrelevant information, enabling exceptional image customization without cumbersome tuning or relying on multiple reference images. |


|
DIScene: Object Decoupling and Interaction Modeling for Complex Scene Generation
Xiao-Lei Li✱, Haodong Li✱, Hao-Xiang Chen, Tai-Jiang Mu, Shi-Min Hu
SIGGRAPH Asia 2024
DIScene is capable of generating complex 3D scene with decoupled objects and clear interactions. Leveraging a learnable Scene Graph and Hybrid Mesh-Gaussian representation, we get 3D scenes with superior quality. DIScene can also flexibly edit the 3D scene by changing interactive objects or their attributes, benefiting diverse applications. |

|
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang✱, Xin Yang✱, Jiantao Lin, Haodong Li, Xiaogang Xu, Ying-Cong Chen
CVPR 2024 Highlight
We present LucidDreamer, a text-to-3D generation framework, to distill high-fidelity textures and shapes from pretrained 2D diffusion models with a novel Interval Score Matching objective and an advanced 3D distillation pipeline. Together, we achieve superior 3D generation results with photorealistic quality in a short training time. |

Academic Service
|
Education & Working |
|
|
University of California San Diego
(2025/09 - Now)
Doctor of Philosophy Department of Computer Science and Engineering |
|
Adobe Research
(2026/06 - Now)
Research Scientist Intern Imaging and Languages Organization |

|
Tencent Hunyuan
(2025/05 - 2025/09)
Research Scientist Intern Center of 3D Generation |
|
Hong Kong University of Science and Technology
(2023/09 - 2025/07)
Master of Philosophy Information Hub, Guangzhou Campus |
|
Zhejiang University
(2019/09 - 2023/06)
Bachelor of Engineering College of Control Science and Engineering |